Star Schema vs Snowflake Schema: BI, dbt, and Warehouse Guidance
In one corner: “Star schema. Always. Denormalize everything. Kimball said so.”
In the other: “Snowflake schema is cleaner. More normalized. Your dimension tables won’t bloat. Third normal form is not a dirty word.”
The problem is that the “star vs. snowflake” debate happens eight months later, when the dashboards are already broken.
Why this decision doesn't get made first
Joe Reis — author of Fundamentals of Data Engineering — ran a State of Data Engineering survey across 1,101 practitioners in early 2026, and the modeling chapter is bleak. 89% report active pain with their modeling approach. Only 28% still practice Kimball-style dimensional modeling at all. 17% admit to pure ad-hoc table creation. And the teams that skip the design step pay for it later — 38% of their week disappears into firefighting, roughly twice the rate of teams with a real semantic model.
The interesting part isn't that teams skip modeling. It's the reasons they give: 59% blame pressure to move fast, 51% blame lack of clear ownership, 39% blame difficulty maintaining the model over time, 19% blame the tools. Reis's own read is sharp — only 19% blame tools, so the rest is on leadership. He's right. But there's a quieter point hiding inside those numbers: when the "design phase" of a warehouse runs into weeks of Lucidchart and erwin, "we don't have time to model" is actually true. The 59% citing speed pressure aren't all making excuses. They're under real deadline pressure, and the design tools available to them genuinely take too long.
The wider industry has been circling the same diagnosis for two years:
Three blockers repeat across that body of work:
- The tools punish you for trying. Lucidchart turns design into pixel-pushing; erwin's learning curve runs into weeks; dbdiagram demands a DSL. None of them are database-aware enough to keep the diagram in sync with the code, so the artifact dies the week after the meeting.
- The infrastructure made "later" look free. Cheap cloud storage and ELT reframed "land raw, figure it out later" as agile. It wasn't — it was deferred firefighting — but the case for upfront modeling kept losing the time-to-first-dashboard argument.
- Nobody owns the model past sprint two. Without a place the design lives and can be edited in minutes, the artifact ossifies and the warehouse drifts away from whatever the original architect intended.
TalkingSchema was built for blockers #1 and #2. It doesn't pretend to fix #3 — ownership is a leadership problem, not a software one — but on the first two, it attacks the friction on both axes the industry kept naming: the time cost and the design experience itself.
Your whole team works on the same surface in real time as the model takes shape. The "design phase" is no longer a multi-week project — it's one collaborative conversation, with the canvas walking grain trade-offs, flagging mistyped SCD columns, and re-deriving every relationship before a single dbt model gets written.
Where the decision lives in your stack
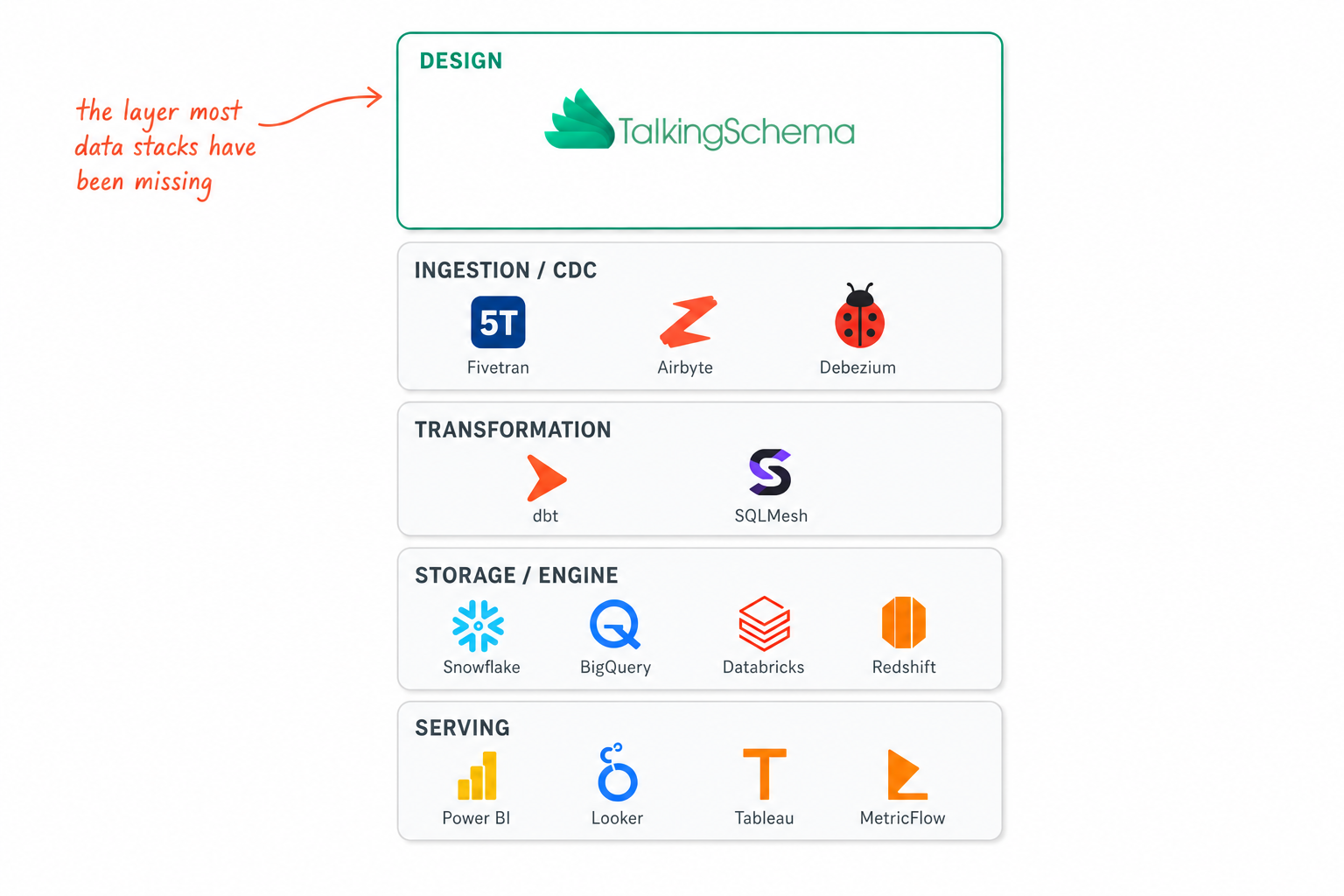
Design done well → every tool below inherits the topology it was optimized for.
Design done poorly → every tool below pays a tax: drifting snapshot configs, multi-hop BI relationships, semantic-layer overrides that quietly contradict the warehouse.
Take a trading firm
There are eight OLTP source systems on different cadences, with different owners and different politics; a BI stack of Power BI, Looker, and dbt's MetricFlow; and a quarter to ship a warehouse those tools can actually query.
A real production estate would run five times this size — Bloomberg and Refinitiv for market data, DTCC and Euroclear for clearing, per-desk OMS/EMS variants, dozens of internal masters with their own data politics — but the warehouse decision below compounds from whatever shape this layer has, regardless of size. We kept this one lean so the design that follows fits in your head.
The obvious first ask:
"Given the source landscape above, design a warehouse my team's BI stack — Power BI, Looker, dbt's MetricFlow — can query without fighting it."
TalkingSchema didn't have to guess at the shape — the prompt named Power BI, Looker, and MetricFlow, and every one of them was built around stars. The proposal is the deterministic answer to the question you asked.
The interesting work isn't reading the proposal. It's interrogating it. Three questions worth asking out loud before you accept what it proposed.
"What changes if fact_trade is order-grain instead?"
Venue-level execution-quality analysis goes away. Partial-fill behavior collapses into an average. Price-improvement metrics no longer derive. Parent-order context is still recoverable through
order_id— but every per-execution analytic loses resolution.
Most teams land back on fill-level the moment they see the trade-off laid out. Grain is the single most expensive conversation to defer and the cheapest one to have here, because you can instantly audit and iterate.
"Audit the SCD assignments across every dimension. Flag anything over-engineered as Type 2 or under-engineered as Type 1."
Reviewed 47 dimension columns across 6 dimensions. Reclassification proposed on three:
dim_security.security_name— currently Type 2, recommend Type 1. Name changes (e.g. Facebook → Meta) are display-only; no analytic joins through the historical name.dim_account.mifid_category— currently Type 1, recommend Type 2. Regulatory category changes affect retrospective reporting eligibility and need a versioned audit trail.dim_trader.email— currently Type 2, recommend Type 1. Email changes are SSO-administrative; no fact joins through email.All other 44 columns hold their current assignment.
What's actually doing the work in that exchange isn't the canvas — it's the context behind the schema. Grain, SCD type, owner, intent: every interrogation above only resolves because the schema carries those facts with it, not just its structure. That discipline — keeping schema context durable as the schema evolves — is what makes agentic modeling actually possible.
Column-level SCD is one critique. The structural one is harder to see. dim_security is hiding a four-level hierarchy:
sector (12 rows)
└── asset_class (85 rows)
└── security_type (320 rows)
└── security (2.4 million rows)
The star schema denormalizes all four levels into one wide table. That holds until FINRA and MiFID II reporting need an independent SCD2 audit trail at every level of the chain — at which point a single GICS reclassification at sector has to materialize as 2.4 million new dim_security rows, and one dimension is now carrying four overlapping SCD2 tracks under a single schema.
Snowflake was built for this:
"I need sector reclassifications to be auditable independently of dim_security. A GICS restructure shouldn't force a denormalized rewrite of every security row. Show me a snowflake variant — keep the same grain, the same surrogate keys, and the same ISIN-keyed business key."
dim_securitysplits intosecurity → security_type → asset_class → sector.
dim_accountsplits intoaccount → account_type / client → client_segment.
The cost is immediate: fact_trade now reaches sector_name through three hops. Three extra relationships in Power BI. Three extra joins per LookML query. Three extra surfaces where a fan-trap can quietly multiply your numbers.
In exchange, the 2.4-million-row problem disappears: a GICS reshuffle is a single-row insert at dim_sector with a new surrogate key, and the same shape covers a client AML re-tier — one dim_client write replaces what would otherwise touch every account that the client holds. SCD2 history lives on the hierarchy node, not smeared across the leaf.
That makes the real question not "star or snowflake" but "which hierarchies move often enough, and need audit footprints sharp enough, to earn the cost?" Hand TalkingSchema the actual frequencies and it flips the call per dimension:
"We re-tier clients ~12 times a year. GICS restructures hit every 18 months. Compliance runs weekly hierarchy-only queries on dim_sector but never on dim_account_type. Re-recommend SCD shape per dimension."
The recommendation comes back specific:
Snowflake
dim_sector— 18-month restructure cadence plus weekly compliance-only queries on the hierarchy justify the audit footprint and the dedicated entity.Snowflake
dim_client— 12 re-tiering events per year compound rapidly in a denormalized account dimension.Star all six other dimensions; their change cadence doesn't pay back against the extra join cost.
That means the right design isn't on the snowflake canvas either. The two shapes belong in different layers of the same pipeline, and the next prompt is the one that asks for the synthesis:
"Combine them. Snowflake the hierarchies that earn it in the layer that needs auditability. Keep stars in the layer Power BI queries. Show me how it maps to a real dbt project."
Sources land via Debezium (OMS, securities master, accounts), Fivetran (CRM, reference data), and Airbyte (clearing, counterparty). Past the landing zone, the warehouse splits into three named schemas — each holding the shape that layer was actually optimized for:
Schema Shape Purpose dbt materialization staging1:1 source copies Cast, rename, dedupe; keep source business keys ( isin,account_bk,client_bk) so lineage stays unambiguousView intermediateSnowflake hierarchy SCD2 audit history — sector reclassifications and client AML moves are single-row inserts with full source lineage Snapshot martStar What Power BI / Looker / Tableau / MetricFlow query; intermediate history flattened to one row per dim version Table (incremental)
Engineers defending "snowflake schema" are usually defending the intermediate layer. BI teams insisting on "star" are insisting on the mart layer. Both are right about different layers — and the layered canvas puts the seam on screen instead of leaving it to a Slack debate that runs for a quarter.
dbt didn't invent layering; what's new is holding the whole pipeline on one canvas so the seams are interrogable before they ship. Two prompts worth running before you sign off.
"Trace the lineage of an ISIN from source to BI."
oms.orders.security_isin → stg.orders.security_isin → int.dim_security_history.isin → mart.dim_security.security_bk. Same business key, four hops, every model the chain passes through.
That walk is what every analytics-engineering interview asks about and almost no production warehouse can produce on demand.
"A client holding 500 accounts moves from AML risk tier 2 to tier 3. Walk me through the cost in each of the three architectures."
Architecture Cost of the AML risk-tier change Star mart alone 500 new SCD2 rows in dim_account, one per account versionSnowflake variant One-row insert in dim_clientLayered architecture One-row insert in int.dim_client_history; the next mart refresh batches the denormalization into all 500dim_accountrows
Same business event, three architectures, three different costs — paid in the place each architecture asks for it. For any team carrying both BI demands and audit demands — roughly every data team past the seed-stage Looker dashboard — the layered shape is the one that ships.
The Snowflake data platform and the snowflake schema design pattern share a name but are unrelated. Snowflake (the company) actually recommends star schemas in its documentation and ships sample datasets in star schema. Don't let the naming coincidence influence the decision.
What actually matters
Star wins for BI. Snowflake wins for surgical normalization in the right layer. The layered project wins more often than either one alone. But all three answers are downstream of whether you got the grain right on every fact, kept your dimensions conformed across facts, and put each shape in the right layer of the pipeline.
The next grain debate, the next SCD audit, the next snowflake-vs-star call — bring them to TalkingSchema. Let your schema talk back.
Related Reference Documentation & Resources
To dive deeper into database schema design, checkout our curated resources and tool guides:
- ORM & Type Safety: Read How to Convert Schema to Code with Prisma, Drizzle, and TypeScript to solve the stale type problem forever.
- Compare Tools: Explore TalkingSchema vs QuickDBD comparison to see multi-framework schema modeling versus text-to-diagram sketching.
- Compare Tools: Read the TalkingSchema vs Diagrams.net (draw.io) comparison to see relational schema design versus generic shape drawing.
- Migration Safety: Master zero-downtime database migrations with the expand-contract pattern to safely update schemas in high-scale environments.
- Product Workspace: Launch the interactive TalkingSchema Modeling Workspace to build, review, and export your database designs instantly.