Kimball vs Inmon vs Data Vault 2.0: Data Warehouse Architecture Guide
Every data team eventually walks into the same room.
Someone is convinced Kimball is dead and cloud storage fixes everything. Someone else is just as convinced that Inmon is the only serious enterprise architecture. A third voice slides in with "Data Vault 2.0 — hubs, links, satellites, audit-ready, future-proof." Forty minutes later nothing has been decided, six weeks later nothing has been built, and the dashboards the business asked for in Q1 are now a Q3 problem.
Here's my promise: this post will help you pick an approach the way an architect picks a structure—not like a sports fan picking a jersey.
The reason this argument runs for six weeks
The design phase has been broken for two decades. Joe Reis's State of Data Engineering survey of 1,101 practitioners earlier this year puts 89% in active pain with their modeling approach — and the reasons are always the same three: no time, no clear ownership, tools that punish anyone who tries.
So nobody prototypes the three options against a real source estate inside a sprint. The choice gets made on whoever's loudest at the whiteboard — and that's how warehouses end up over-engineered for governance nobody needed, or under-engineered for the audit trail everyone will need next year.
The solution isn't more conviction. It's the ability to stand up all three architectures against the same source landscape, look at the seams, and pick the one that survives the constraints you actually live with. That's the work TalkingSchema was built for — not pretty diagrams, but compressing the design phase from a multi-month exercise into one collaborative conversation with canvases you can interrogate before a single dbt model gets written.
The company we're going to walk through
Imagine a mid-market commerce business with 30 operational tables across eight subsystems:
- CRM + catalog own identity, B2B accounts, customer addresses, support cases, products, SKUs, categories, and suppliers.
- Sales + billing + finance own carts, orders, payments, invoices, refunds, chargebacks, and adjustments.
- Fulfillment + inventory + marketing own warehouses, carriers, shipments, stock movement, reservations, campaigns, promotions, and attribution.
That is the real problem: every team owns a slice of the truth, and no two slices define "customer" or "order" the same way.
So the architecture conversation has to start here — with the operational reality the warehouse must absorb, not a whiteboard sketch or an end-state mart.
Source schema
Spend a moment with the ERD. Read the DBML notes. Notice which subsystem owns money, which owns identity, and which only knows half of any given customer's story. Every methodology decision downstream is a different answer to: how do we glue these eight subsystems into one coherent business?
What we're going to do next
Every analytical platform has to do the same three jobs — capture what happened, integrate it into shared meaning, serve it to humans and machines. The “methods” differ mostly in which job they optimize first. We're going to walk this exact source estate through three architectures and then converge on the mart layer they all eventually feed.
Architecture deep dives
The deep dives below are meant to be read as one sequence. Each page takes the same source estate through a different architectural instinct, uses TalkingSchema to make the model visible, and asks the practical questions you would want answered before committing to the design.
Architecture Deep Dives
Part 1 — Kimball Dimensional Modeling: Make the Business Question Easy
When I put on my Kimball hat, I start with the question the business is desperate to answer: what was net revenue by product category, channel, and month?
The first decision is how detailed the answer needs to be: one row per entire order, one row per individual item within an order, or one row per customer summarized across a month. Kimball calls that level of detail the grain. For a revenue question, the most honest grain is one row per item sold — one product, in one purchase, at one moment.
Once the grain is decided, the rest of the table almost falls into place, with each row recording the numbers we want to add up — revenue, quantity, discount, tax, and margin — for that one product, in that one purchase, at that one moment. Kimball calls this the fact table: every row is one observed fact about the business.
But the fact table on its own only gives us numbers, so to understand who bought, what they bought, when it happened, and where it came from — the four questions every revenue analysis eventually asks — we need companion tables that carry the context. Kimball calls these dimensions: context tables used to filter or group the numbers, and for our revenue question they will be customer, product, date, and channel.
Once the grain, fact, and dimensions are clear in your head, the model itself is seconds away — just ask TalkingSchema:
First star
"Review the source schema, design me a star to answer net revenue by product, customer, channel, and time. Walk me through the grain, the dimensions, and the trade-offs you're making."
Using the commerce source schema, I built a star around your revenue question. The fact table sits at order-line grain — one row per item sold, in one order, at one moment — and points to four supporting dimensions: customer, product, channel, date.
The fact table carries the measurable business activity: revenue, quantity, discount, tax, and margin. The dimensions carry the surrounding business context — who purchased the item, what product was sold, through which channel, and on what date.
Two modeling choices worth flagging:
- Product sits at the SKU level, with brand, parent product, and current category flattened in.
- Customer and product are stored as the current view only — no historical tracking yet — because the first dashboard's job is to reflect today's reality.
Left out on purpose: payments, refunds, chargebacks, invoices, shipments, inventory, promotions, support cases, and attribution. Each one lives at a different grain in its own business process, and each will get its own fact table when the business asks for it.
But this first star also earns its limits quickly.
Finance will ask why the revenue we recorded on a sales report doesn't match the cash that actually landed in the bank. Operations will ask which warehouse is shipping orders late. Marketing will ask whether a promotion brought in genuinely new sales, or just gave a discount to customers who would have bought anyway.
None of those questions are really about the sale itself. They are about payments, shipments, and customer behavior — different events, in different systems, often on different days. Piling more columns onto the table that records sales would force three unrelated stories onto a single row, and the numbers stop adding up the moment two people slice the data two different ways.
That is when I broaden the design into the conformed dimensional warehouse we can actually publish across the business, so the schema can answer multi-domain questions.
Conformed bus
So let's ask TalkingSchema to broaden the star:
Let's extend our star model into the full conformed bus.
Keep each business process at its own grain: sales, cart abandonment, payments, refunds, chargebacks, invoices, shipments, shipment lines, inventory snapshots, inventory movements, support cases, and attribution touches.
They should all share conformed dimensions for customer, B2B account, product, category, supplier, date, channel, warehouse, carrier, payment method, promotion, and campaign.
I extended the model into twelve conformed dimensions — date, customer, B2B account, product, category, supplier, channel, warehouse, carrier, payment method, promotion, and campaign — drawn from the source schema and shared across every fact in the warehouse.
Each business process keeps its own fact at its own grain:
- Sales at order-line grain for booked revenue.
- Cart abandonment at cart grain for funnel and recovery analysis.
- Payments, refunds, and chargebacks as three separate facts so cash, refunds, and disputes stay clean.
- Invoices for B2B billing and payment tracking.
- Shipments split into header (carrier and SLA) and line (fulfillment) grains.
- Inventory as daily snapshots plus an additive movement ledger.
- Attribution touches for multi-touch revenue attribution.
- Support cases for customer issue tracking.
- A promotion bridge so a single order line can carry multiple promotions, and the same promotion can apply to many lines.
I gave eight dimensions full historical tracking — customer, account, product, category, warehouse, carrier, promotion, and campaign — so the warehouse can answer "as-of" questions against the state of the business as it actually was.
The model now covers sales, payments, refunds, shipments, inventory, support, and more — while sharing the dimensions:
- One customer. Sales, finance, support, and marketing all point to the same person — not different versions of "the customer" defined in each team's own system.
- One calendar. Every report aligns to the same week, month, and quarter, no matter which team built it.
- One warehouse. A given building is the same physical location whether the question is how fast it ships or how much stock is on its shelves.
Star schema: when the query gets boring
When the design is right, the final query feels almost boring:
select
d.year,
d.month_name,
ch.channel_name,
p.category_name,
sum(f.net_amount) as net_revenue
from dw.fact_order_line f
join dw.dim_date d
on f.order_date_key = d.date_key
join dw.dim_channel ch
on f.channel_key = ch.channel_key
join dw.dim_product p
on f.product_key = p.product_key
group by 1, 2, 3, 4
order by 1, 2, 3, 4;
That boredom is a feature. It means the complexity stayed where it belongs — in the modeling decisions — and never leaked into every downstream query.
Kimball conformed bus: where this lands
And that's the takeaway: the simple star wasn't "wrong." It was the right first move — a clean, fast path from source data to trusted sales reporting. The conformed bus is what happens when the organization matures from one question to many. That's why Kimball is such a strong fit for BI teams, semantic models, dashboard workloads, and "I need usable answers next sprint" situations.
But the way the bus integrates is worth being honest about. It works through mutual agreement: every mart — every business-facing reporting slice — builds its own dim_customer in its own pipeline, with every team promising to conform to the same shared spec for columns, business rules, and grain. That spec lives in a document — but whether it's actually being followed across every pipeline is a question of trust. This practice holds only until the first reader of the warehouse is compliance, audit, or master data management. At that point, mutual agreement isn't enough — the organization needs one governed definition of "customer" to exist before any mart touches it.
That isn't a Kimball failure. It's a different problem, and it's exactly the one Inmon was written to solve. That's where we go next.
Part 2 — Inmon Enterprise Data Warehouse: Integrate Before You Decorate
When I put on my Inmon hat, I start with the question every auditor, compliance lead, or risk officer eventually asks: where does the official record live, before anyone turns it into reports and dashboards?

An Inmon warehouse is organized around what he calls subjects — the major things a business actually cares about: customers, products, accounts, orders, shipments, and so on. At the center, every subject has one official version, carrying the full history of how it has changed over time. The result is a centralized model designed to represent enterprise meaning consistently, so downstream consumers query a curated core rather than having to reconcile sources themselves.
That integrated center is called the Corporate Information Factory (CIF), or Enterprise Data Warehouse (EDW). Think of it as the backbone that brings enterprise data together, organizes it, and makes it reusable. Let’s see how our source would transform into a CIF model.
The integrated core
"Review the commerce source schema and design me an integrated Enterprise Data Warehouse core in Inmon's style."
For our commerce source schema into an integrated EDW, I consolidated every operational entity into 29 integrated subjects across 8 business domains — identity, catalog, sales, money in, money out, fulfillment, inventory, marketing.
Each subject carries three things by design:
- A stable key of its own, so the warehouse owns every row's identity independently of the source system that produced it.
- An integrated identity, so the customer who appears in CRM, sales, billing, and support resolves to one governed entity in the warehouse.
- A built-in history, so the same row carries both "what is true today?" and "what was true on March 15?"
Every row also records the source feed that produced it — the audit trail for the moment when sales and finance argue about the same number.
Corporate Information Factory: how Inmon ships
The shape of the EDW is doing several jobs at once. Each one is a payoff of Inmon’s discipline.
Subject-oriented. Tables organize around the business — customers, orders, products — not around source systems. Replace the CRM next year and the warehouse schema doesn’t have to move.
Integrated. Conflicts that exist in source — naming, formats, what "active" means — get resolved here, once. Marts inherit the resolved form rather than re-litigating it.
Time-variant. Every important business state is tied to when it was actually true. A customer who was Pro in Q2 and Enterprise in Q3 keeps both, so Q2 reports use the Q2 state.
Non-volatile. History is preserved, never rewritten. The old Pro record stays available for audits, reconciliations, and historical reporting long after the customer moved on.
The practical version of Inmon — the one that ships — looks like this:
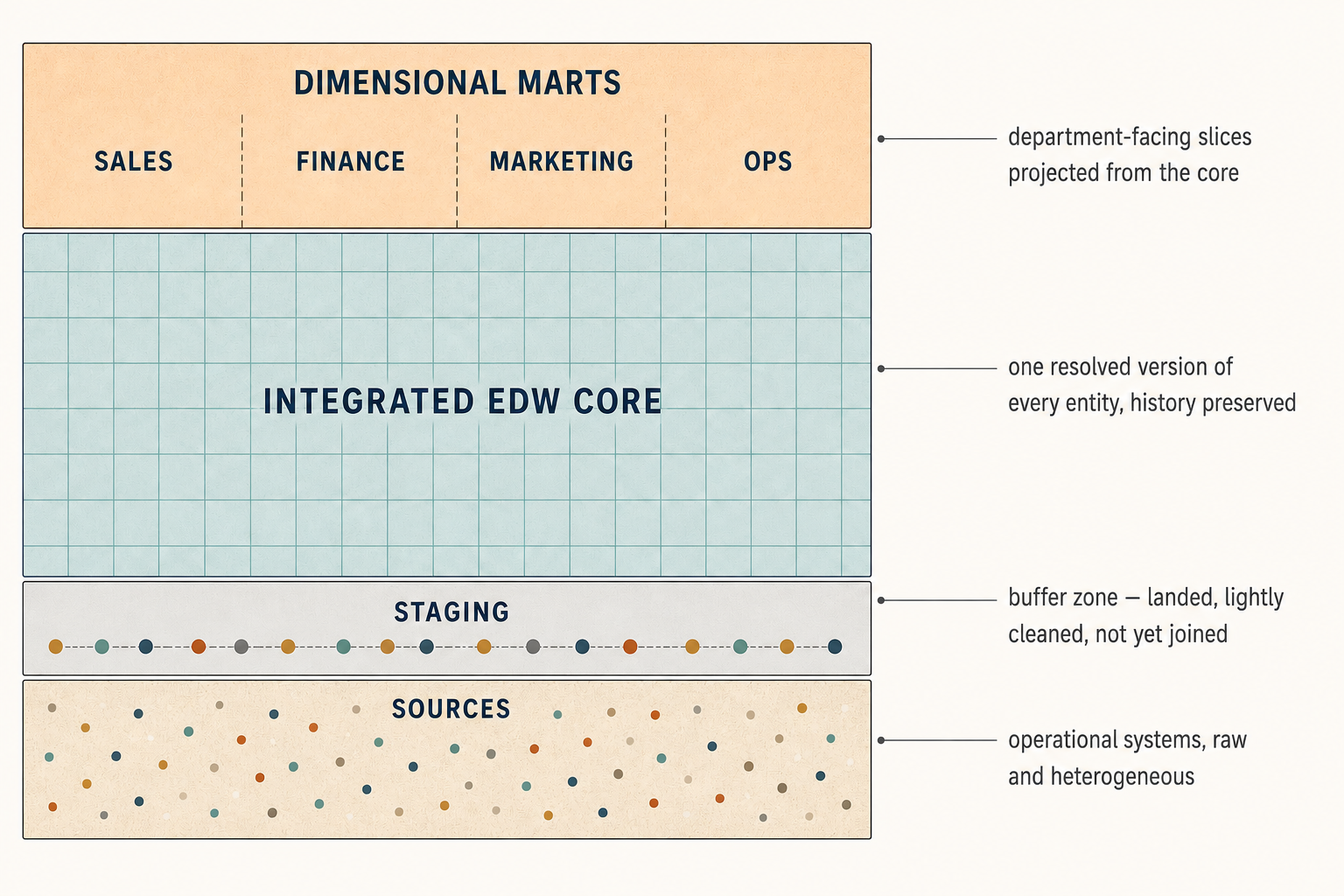
As you can see, the EDW is the backbone, while teams still consume data through dimensional marts — the same conformed-bus marts we sketched earlier. The key difference is that these marts are now downstream of an integrated EDW, rather than being fed directly from source systems as they were in the Kimball approach.
The win is cross-domain coherence. The cost is patience.
If my organization has many domains, regulatory pressure, and a warehouse that needs to serve dozens of marts over several years, I want some Inmon DNA in the architecture.
What Data Vault adds
So that's Inmon. What does Data Vault add?
Resilience.
The Inmon EDW works best when the business changes slowly enough that you can design a clean integrated model and keep it stable for a while. That’s realistic in some industries.
But in faster-moving environments, the sources keep mutating: a new payment gateway, a changed refund policy, a switched fulfillment partner, a reorganized product taxonomy, a fresh compliance field. Each one can force the central EDW model to be revisited.
At that point, the normalized EDW starts to feel fragile. The model is elegant, but it depends on a level of source stability the business may not actually have.
Data Vault starts from a different assumption: the source estate will keep changing, so the warehouse should be designed to absorb change rather than constantly be redesigned around it.
That's where we go next.
Part 3 — Data Vault 2.0 Hub, Link, Satellite: When the Source Estate Won't Hold Still
Inmon's beautiful normalized core makes one big assumption: the source estate — the operational systems that feed the warehouse (CRM, billing, fulfillment, finance, and so on) — stays still long enough that a careful integration layer can be built once and last for years.
That assumption holds in some industries — utilities, fixed-income trading, slow-moving regulatory environments. In most others it doesn't. Sources keep mutating: a new field here, a new partner there, a renamed status, a reshuffled hierarchy. Each change is small on its own. The cumulative cost is not.

One field, two postures
To see what those two postures actually mean in practice, take the smallest source change you can think of. Marketing rolls out a loyalty program and adds one new field to the customer record: loyalty_tier, with values like Bronze, Silver, and Gold. Nothing else changes.
What Inmon has to do. Customer lives in one canonical table — edw.customer — so honoring the new field means altering that table. Schema migration. A backfill decision (what tier do historical rows get?). A quiet ripple through every mart that reads from customer. The change is small, but it touches the spine of the warehouse, and the spine is load-bearing.
What Data Vault does. In a Data Vault, customer isn't one table at all. The model is built from three kinds of object, each with a single job:
- A Hub — a tiny table holding nothing but the durable business key for "customer". Stable, almost never changes.
- A family of Satellites — separate tables, each one carrying a group of attributes that tend to change together (profile in one, contact info in another, billing preferences in another), all keyed back to the same Hub. This is where attribute changes land.
- A set of Links — small tables that connect two Hubs to represent a business relationship (customer ↔ order, customer ↔ account). Not in this example, but you'll see them in the canvas below.
So, when Marketing adds loyalty_tier, no existing table gets altered — not the customer Hub, and not any of the existing customer Satellites (profile, contact, billing). You add a new Satellite — call it sat_customer_loyalty — and key it to the same customer Hub. Old marts keep reading the old satellites and produce the same numbers they always did. New marts join the new satellite when they need the new field.
The same pattern handles change over time, not just new attributes. When a customer's tier later moves from Bronze to Silver, the Satellite just gets a new row stamped with the load timestamp — the old row stays put. History is preserved by accretion, never by overwrite.
That was one field, one new Satellite. The full commerce estate has many more shapes to absorb — same source schema as the Inmon core, same eight subsystems, but a fundamentally different posture toward change. Let's hand it to TalkingSchema.
Raw vault
"Use the same commerce source schema. Design the integrated core as a Data Vault 2.0 raw vault — hubs for durable business keys, links for business relationships, satellites for descriptive context and history."
Walking through the commerce source schema, every stable entity became a Hub (24 in total), every business relationship between those entities became a Link (27), and every group of attributes that change at the same cadence became a Satellite (30).
The Hubs carry the durable business keys — a customer, an order, a payment, a product, a shipment, and so on. Each Hub holds only the business key and the load metadata. Nothing else. That minimal shape is what makes a Hub stable: it has nothing to drift on.
The Links carry the business relationships between those Hubs. Most are simple two-way joins (
order ↔ customer,shipment ↔ carrier). A few are deliberately many-way —refund ↔ payment ↔ order, for example, because in the source estate a refund is traceable to both the original payment it returns and the order it cancels. Every business relationship in the source gets its own Link, so the model stays faithful to the actual shape of the business.The Satellites carry the descriptive context and how it moves over time. I grouped attributes by how often they change together — a customer's profile in one Satellite, their contact info in another, billing preferences in a third — so each Satellite can be loaded at its own natural cadence. Each one keys back to its Hub via
(hk_*, load_dts). New values land as new rows stamped withload_dts. New attributes from a source upgrade land as new Satellites alongside the existing ones.Every load is append-only and idempotent. The model grows by accretion.
Business vault
The cost, of course, is that nobody can query this directly. Raw vault is built for truth preservation, not for human consumption.
That’s why we add a business vault: a derived structure on top of the raw vault that pre-resolves the access patterns analysts hit every day.
The business vault focuses on three query patterns that show up in almost every mart:
| Helper | The question it answers | Concrete example |
|---|---|---|
| PIT (point-in-time) tables | "What did this entity look like on date X?" | Customer's loyalty tier on the day they placed an order |
| Current-state projections | "What does this entity look like right now?" | Today's full product catalog without walking history |
| Resolved bridges | "Walk me from this entity to its full context." | order_line → variant → parent product → category, in one read |
Three helpers, three query patterns. Let's ask TalkingSchema to put them on top of the raw vault.
"Now add the business vault helpers. PIT tables for historized point-in-time lookups, current-state projections for cheap access, and bridge helpers that flatten the multi-hop paths the marts will need."
On top of the raw vault, I added a business-vault layer with three classes of helpers — each one shaped around a query pattern the marts will hit every refresh.
The PIT (point-in-time) tables pre-resolve Satellite history for each historized Hub — customer, account, product variant, category, campaign, promotion, and a handful more. A mart asking "what did this customer look like on March 15?" resolves it as a single join against the customer PIT.
The current-state projections flatten the latest row of every relevant Satellite into a single wide row per Hub.
bv.current_product_variant, for instance, stitches the variant's own attributes together with the parent product, supplier, and current category. One read, no joins. Most marts only need today, and these give them today.The resolved bridges collapse the multi-hop paths the marts hit every refresh.
bv.bridge_order_line_resolvedwalks line → order → variant → parent product → category in one lookup, so the sales mart resolves the full order-line context in a single read.bv.bridge_order_lifecyclestitches first-occurrence timestamps from payment, shipment, refund, and chargeback into one accumulating snapshot, so the order-lifecycle dashboard becomes a single query.One discipline holds the whole layer together: the business vault never overwrites the raw vault. It's a derived access layer. If business rules change, the business vault gets rebuilt. The raw vault stays immutable.
One upgrade, four layers
A customer upgrades from Pro to Enterprise. One business event — watch where it lands in each layer:
-
Raw vault —
sat_customer_profileis the Satellite table that stores customer tier history. The load adds one new row to that table (Enterprise, with a load timestamp), keyed back to the same customer Hub. The older Pro row stays in that same Satellite table — raw vault never deletes or overwrites history. -
Business vault — PIT —
pit_customeris a helper table that pre-slices Satellite history by date. On its next refresh, it registers the new Enterprise row fromsat_customer_profile, so an order from March still resolves to Pro and an order from this week resolves to Enterprise. -
Business vault — current state —
current_customeris a helper table that collapses "today only" into one row per customer. That row updates to Enterprise — dashboards that only need the present read this table instead of walking Satellite history. -
Sales mart — joins through
bv.bridge_order_line_resolvedand produces the right answer for last quarter (Pro) and this quarter (Enterprise) without anyone touching a query.
No migration code. No overwrites. No broken history.
Raw vault preserves history. Business vault makes that history queryable. Marts make the queryable history consumable.
Raw vault vs business vault: where this lands
Inmon says you need a governed integration layer. Data Vault says: yes, and here's how to build that layer so it survives the next ten years of source mutation.
Both the Inmon EDW and the Data Vault raw + business vault stack eventually feed the same family of dimensional marts — the simple star-shaped tables your dashboards and reports actually run on.
Next, let’s walk through the core dimensional marts that usually bring this architecture to life.
Part 4 — Data Mart Architecture: Where Every Methodology Converges
This is the part people pretend is controversial, and it really isn’t.
No matter which core you pick — Inmon EDW, Data Vault, or "we'll figure it out later" — the business gets its answers from dimensional marts.
Same company. Same source systems. Different upstream discipline.
Same downstream promise: clean, boring, trustworthy marts where analysts, finance teams, operators, and executives can ask simple business questions:
What sold? What slowed down? Where did margin leak? Which customers are drifting? Which orders are stuck?
Seven marts
For our commerce company, I would not stop at one star schema.
That would be too toy-like. Real companies do not just need "sales reporting." They need several analytical viewpoints that still agree with each other:
- Sales mart — what got sold, to whom, through which channel, and for how much
- Finance mart — what got paid, refunded, disputed, and settled
- Fulfillment mart — what got shipped, delivered, delayed, and at what cost
- Supply mart — what stock position looked like over time
- Customer mart — who is valuable, growing, declining, or at risk
- Marketing mart — which campaigns and promotions influenced orders
- Operations mart — what the order lifecycle looked like end to end
I also would not build each mart in isolation. I would keep a shared conformed dimension layer in mart_common.*, then let multiple facts plug into it.
Let's build it with TalkingSchema.
Build the mart layer
"Build the dimensional mart layer that includes: sales, finance, fulfillment, supply, customer, marketing, and operations. Put shared conformed dimensions in mart_common.*, keep the important facts at the right grain."
I built the mart layer as seven business-facing schemas — sales, finance, fulfillment, supply, customer, marketing, and ops — all sharing one conformed dimension hub in
mart_common.Twelve conformed dimensions live there: customer, account, product (at variant grain), category, supplier, channel, date, warehouse, carrier, payment method, promotion, and campaign. Eight carry Type-2 history —
scd_start_date,scd_end_date, andis_currenton customer, account, product, category, warehouse, carrier, promotion, and campaign — so the marts can answer "as-of" questions directly.Each business process from the source got a fact at the grain it actually records: order-line sales, cart abandonment, payment-id cash events, refunds, chargebacks, invoices, shipment header and line, daily inventory positions, inventory movements, support cases, and attribution touches.
Two shapes worth calling out:
bridge_order_line_promotionhandles the many-to-many between order lines and promotions.fact_customer_monthly_snapshotis a periodic snapshot — chargeback exposure and open-case count on one row for churn signals.fact_order_lifecycleis an accumulating snapshot — one row per order, milestone dates filled in as it moves from created through paid, shipped, delivered, refunded, and charged back.
Two lineages, one mart
This is the part that makes the architecture feel less mysterious.
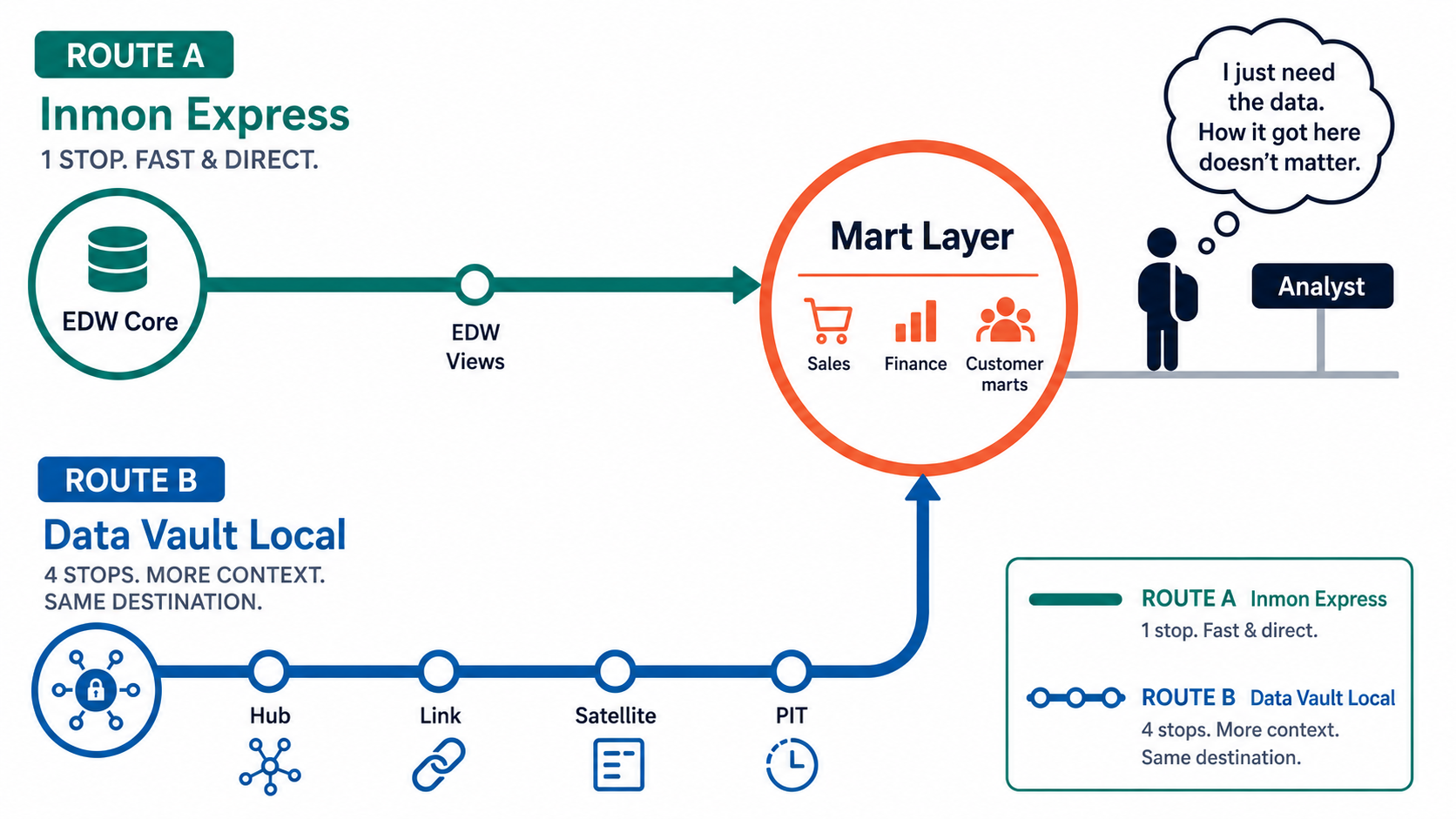
Whether the source foundation is an Inmon-style EDW or a Data Vault, the final table can look the same. But the path to build it changes, because each modeling approach preserves history and connects business entities differently.
The analyst gets simplicity. The ETL team absorbs the complexity.
From an Inmon EDW
Most of the integration work has already happened in clean subject-area tables. Building a mart is mostly a matter of reshaping those integrated tables into facts and dimensions.
edw.customer + edw.account → mart_common.dim_customer
From Data Vault
The same mart table has to be assembled from smaller historical parts: a hub for the business key, satellites for descriptive changes, and helper tables that make the current or as-of view easy to query.
hub_customer + sat_customer_profile + pit_customer → mart_common.dim_customer
Conformed dimensions across three methodologies
The most useful idea I can hand you out of this whole series is not "Kimball vs. Inmon vs. Data Vault." It's this:
A real company needs all three instincts at different layers of the same architecture.
For this one commerce business:
- The source systems are operational and messy — that's the layer everything has to absorb.
- The integrated core is where the company chooses its governance and historization discipline — that's the layer that's Inmon-shaped or Vault-shaped depending on how volatile the estate is.
- The mart layer is where the company chooses clarity and usability — that's the layer that's always Kimball-shaped because that's what BI tools, semantic layers, and human analysts are optimized to consume.
This layered view ends the fake fight between methodologies. Serious teams don't pick one. They pick one per layer, and each choice follows from the constraints that layer has to live with.
Next is where we make that explicit — which constraint maps to which methodology.
Part 5 — Kimball vs Inmon vs Data Vault: The Architect's Decision Framework
Kimball, Inmon, and Data Vault 2.0 aren't three rival religions. They're three different answers to one architectural question:
Where should the hard work happen?
- In the reporting layer, so business users get answers fast?
- In the enterprise integration layer, so the company has one governed backbone?
- In a historized core, so source chaos and audit pressure stop breaking the model?
Five questions that resolve the Kimball vs Inmon vs Data Vault choice
When I'm making this choice for a team, I don't ask "which methodology is best." Best is meaningless without constraints. I ask five questions, and the answers usually point at exactly one synthesis.
1. What is my dominant risk? If the risk is slow BI delivery, Kimball rises. If the risk is enterprise inconsistency, Inmon rises. If the risk is source volatility and auditability, Data Vault rises.
2. Who is my first customer? If it's analysts and BI developers, I need a star-friendly serving model early. If it's governance, risk, or enterprise architecture, I need a stronger integrated core.
3. How often will my source reality change? Stable sources do not need the same level of historized flexibility as constantly mutating ones.
4. What can my team actually operate? The correct architecture on paper is still the wrong architecture if the team cannot maintain it at 2 a.m.
5. What layer am I optimizing right now? Capture? Integrate? Serve? Most arguments disappear once this is answered honestly.
If you only remember one thing, make it this:
These are not three competing “database shapes.”
They’re three different answers to: “Where do we put integration, and when do we pay for it?”
From data warehouse methodology debate to live collaboration
This is where TalkingSchema turns methodology debates into live collaboration, helping your team explore, align, and shape the model together in real time.
Modern source estates are too large to reason about table by table. When you are looking at forty, eighty, or a hundred and twenty tables across multiple systems, the hard part is not drawing another diagram. It is understanding ownership, grain, overlap, change patterns, and which modeling approach will hold up against the reality of your data.
Bring the source systems into a shared modeling workspace where architects, engineers, analysts, and business stakeholders can work from the same context.
Create and compare the approaches side by side, challenge the assumptions, and work through the questions that usually get buried in meetings:
- Which grain choices are risky?
- Which source changes would break the design?
- Which fields need Type-2 history?
- Which tables carry sensitive data?
- What does the downstream team need to build the pipelines?
That is where TalkingSchema starts to matter beyond the diagram. It helps teams translate modeling work into the practical artifacts that drive decisions, alignment, and execution: lineage and impact notes, governance summaries, source-change risk reports, data contracts, security and classification reviews, and source-to-target specs for the ETL team.
The point is not just "here is a pretty schema." The point is:
Here is the design.
Here is why it works.
Here is what can break it.
Here is what each team needs to do next.
The work that used to take three months in Lucidchart and erwin now takes a couple of afternoons. That's not the headline feature. The headline feature is that you actually get to pressure-test different architectures before you commit, which is the thing the modeling debate has been begging for and the tooling has never delivered.
So when you're choosing between Kimball, Inmon, and Data Vault 2.0 — don't pick like a fanboy. Bring the next architecture call to TalkingSchema. Model the options. Prototype the warehouse. Pressure-test against the actual constraints.
Then ship the design that survives.