The Missing Layer in ERD Tools: Why Database Schemas Need Business Context
If you've read our companion piece on ERD tools in 2026, you've seen the seven categories the market currently breaks into — developer tools, enterprise governance platforms, diagramming surfaces, database clients, warehouse modelers, AI-native design tools, schema-as-code. Each is optimized for a different job.
What none of them solve — yet — is the job that matters most as schemas evolve over years: keeping the meaning of a model accurate as the business it describes changes.
This is the piece where we make the case that the next real category in this space isn't a better diagram, a better DBML editor, or a better AI Agent. It's a context-aware modeling system. And it's the bet TalkingSchema is taking.
Disclosure. We build TalkingSchema. This post is the forward-looking post. If you're shopping for a tool to use this week, start with the comparison post. If you want to understand where the category is going, keep reading.
The context gap that makes accurate modeling hard
Every tool reviewed in the tool-comparison post is technically competent at rendering what you give it. What none of them can do is tell you what a schema means — why a column exists, what business decision shaped this table, who made that call and when, what the exceptions are, or whether this field should be used for ARR reporting or only for billing operations.
That gap is why AI-assisted modeling is harder than AI-assisted coding. A coding agent like Cursor can work largely from a codebase because code has tests — if the output breaks, something catches it. AI-assisted modeling has no equivalent safety net. A model can be technically valid and still be semantically wrong. The schema for customer_revenue_events doesn't tell you whether that table should be used for ARR reporting or only for billing operations. The business context does. Without it, AI agents generate plausible-looking models that are quietly wrong in ways that don't surface until someone's board presentation is built on misattributed revenue.
TalkingSchema is building a context layer around schemas to close this gap. No, not another data catalog — TalkingSchema connects to existing catalogs, lineage tools, and metadata systems rather than replacing them. What catalogs don't capture is the living business intent: the Slack thread where someone clarified what recognized_at actually means, the meeting where the revenue operations team decided which table to use for which reporting context, the institutional knowledge that lives in people's heads and gets reverse-engineered by every new engineer who touches the schema.
The design principle: capture context at the moment of need — not upfront.
Most documentation efforts fail because they ask teams to write everything down in advance. TalkingSchema flips this: business intent gets captured only when a modeling decision is actively blocked by its absence.
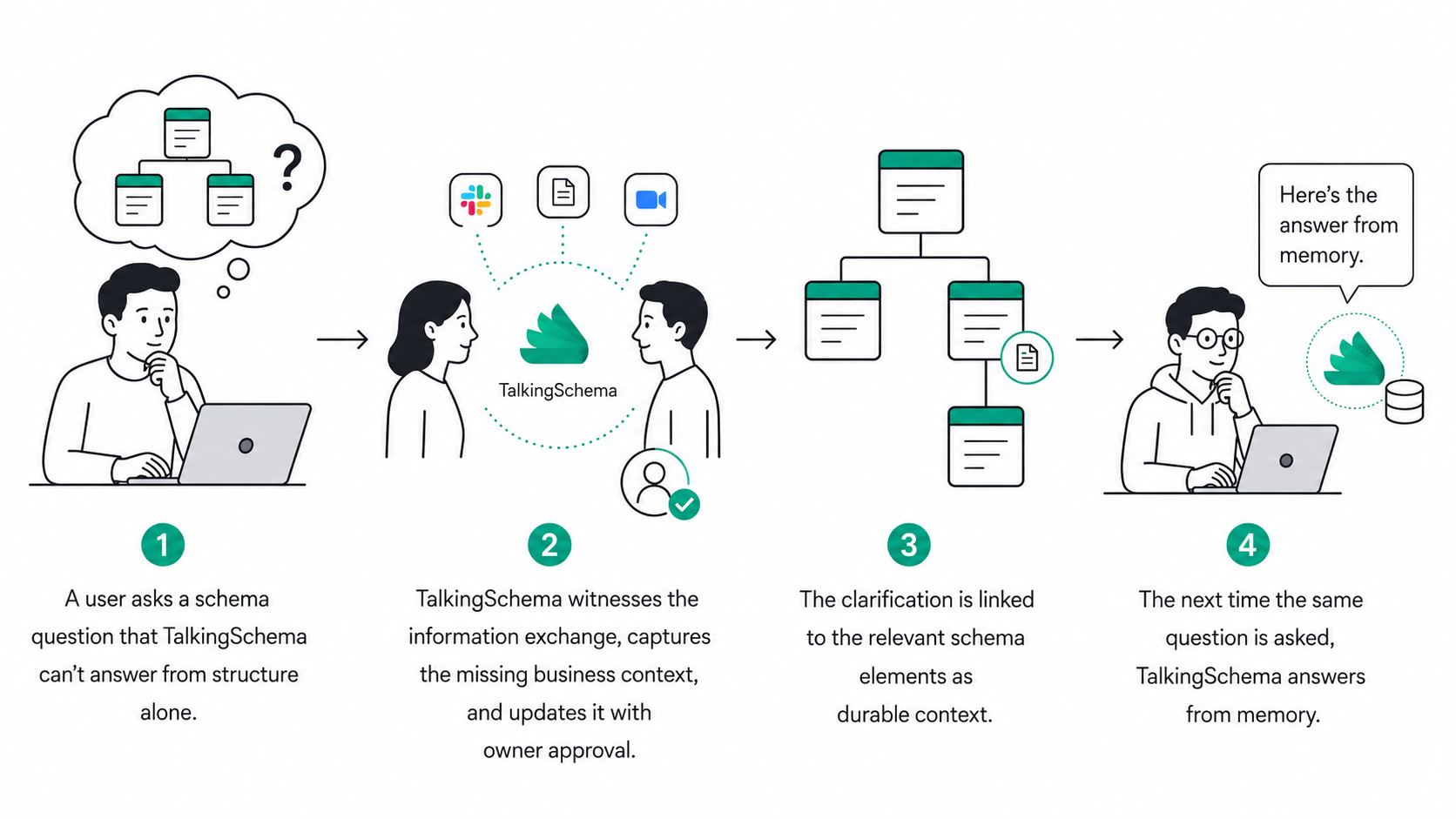
Here's the loop when a decision depends on business policy that isn't in the schema:
 How it fits together — each numbered step below unpacks one stage.
How it fits together — each numbered step below unpacks one stage.
- Detect the gap — TalkingSchema recognizes that the answer can't be inferred from the schema or any connected catalog, so it avoids hallucination — it won't invent confident answers just because it can.
- Find the owner — It identifies the right person: the table owner, the domain expert, or the engineer who last touched this part of the schema.
- Connect the right people — TalkingSchema brings the engineer and the right owner into the same conversation — in Slack, email, Zoom. No "who even owns this table?" detour. No digging through six-month-old Slack history.
- Persist the answer — Whether the resolution happens inline, in a Slack thread, or on a quick call, TalkingSchema witnesses it and permanently links the clarification to the relevant schema elements as reusable, AI-readable context.
Step back from the four steps and the model gets simple: every question is asked in front of TalkingSchema, and every answer is exchanged in front of TalkingSchema. It doesn't need to be told what to remember — it witnesses the work and turns it into reusable memory.
This is what separates a design tool from a modeling brain.
Where the AI-Native Category Is Actually Going: Advanced Modeling
The tools described in the comparison article — TalkingSchema included — currently operate in response to what a user asks. You open a thread, describe a problem, and the AI helps you build a model. That's useful. It's also still fundamentally reactive.
The direction this category is moving is toward advanced modeling: a fleet of agents that tracks change movement across data systems and proactively surfaces model recommendations rather than waiting to be asked.
The workflow looks like this:
- A schema changes — a new table lands, a column is renamed, a relationship is modified.
- An agent evaluates the change and asks:
- What new business activity can now be tracked?
- What existing model does this change break?
- What cross-domain relationship is now exposed that wasn't before?
- The team receives a proposed model ready to review — instead of a data engineer discovering the change weeks later during a modeling sprint.
The agent doesn't just watch a single database. It tracks movement across multiple data systems, understands how changes in billing relate to models in analytics, and surfaces multi-domain proposals that no individual engineer would have the context to generate alone.
The technical precondition for this is the context layer described above. An agent watching schema diffs can produce plausible model suggestions from schemas alone. What makes those suggestions accurate rather than just plausible is accumulated business context: understanding what the data actually means, what the historical decisions were, what the exceptions are.
- Without that foundation, advanced modeling produces sophisticated-looking noise.
- With it, it produces something closer to a modeling agent that genuinely genuinely understands your business.
The goal isn't to replace data engineers. It's to make the modeling decisions they already have to make visible, structured, and reviewable. The agent surfaces the work; the team reviews, rejects, or approves it.
This is a different bet from the rest of the category. erwin and ER/Studio are optimizing for governance at rest. ChartDB is optimizing for documentation speed. SqlDBM is optimizing for warehouse-specific collaboration. We're building toward modeling as a continuous, agent-driven process that responds to how data systems actually change. Other teams may well chase the same direction — but as of this writing it's not in shipping product anywhere we've found.
What This Means for Tool Choice Today
None of the above is a feature you can turn on this afternoon. The reactive design workflow — describe a system in plain English, get an ERD, export to SQL/Prisma/Drizzle — is what TalkingSchema ships today. The context layer is in active development. The proactive multi-agent advanced modeling capability described above is the direction we're building toward, not a checkbox on a pricing page.
So what should you actually do with this information when picking tools in 2026?
- If you're choosing a tool for the next 12 months, use the comparison post. Pick by workflow, not by promises.
- If you're choosing a tool for the next three to five years, optimize for one thing: the schema and the context around it should live somewhere portable and accumulating. If your tool only captures diagrams and DDL, you'll have to rebuild the rest of the model from scratch the day the next category of tooling shows up. That's the lock-in worth worrying about.
- If you're a data team lead at an organization where modeling decisions get re-litigated every six months — because the original decision lives in Slack history, an ex-employee's head, or nowhere — the cost of the context gap is what you're actually paying for today. The question isn't whether you need a context-aware modeling system. It's how long you'll keep paying that cost before the category exists in shipping form.
We think the answer is "not much longer." The shape of the work is clearer than it was a year ago, the underlying AI infrastructure has caught up, and at least one team is building toward it in production. Whether that team is us, an incumbent that pivots, or someone we haven't seen yet — the gap is real, and the next five years of data modeling tooling will be defined by whether and how it closes.
Everything we ship — what's live today and the context-layer and advanced-modeling work as it lands — gets posted to our monthly release notes. Follow it if you want to track where this goes.
Related Reference Documentation & Resources
To dive deeper into database schema design, checkout our curated resources and tool guides:
- ORM & Type Safety: Read How to Convert Schema to Code with Prisma, Drizzle, and TypeScript to solve the stale type problem forever.
- Compare Tools: Explore TalkingSchema vs DBeaver comparison to understand visual schema design versus query client operations.
- Compare Tools: Read the TalkingSchema vs MySQL Workbench comparison to see multi-framework schema modeling versus MySQL-centric administration.
- Migration Safety: Master zero-downtime database migrations with the expand-contract pattern to safely update schemas in high-scale environments.
- Product Workspace: Launch the interactive TalkingSchema Modeling Workspace to build, review, and export your database designs instantly.