Database Normalization Is Not Enough: Context-Aware OLTP Schema Design
The data is right there. The meaning is not.
That gap — between what your OLTP schema stores and what it means — has quietly become the most expensive problem in modern data work. The textbook half is solved. Tables normalize to 3NF, foreign keys check out, migrations ship without locking, and most senior engineers can stamp out a clean transactional schema in their sleep.
The unsolved half is everything the schema doesn't say. The intent behind a column. The grain of a row. The business definition of an enum value. The mutability of a foreign key target. None of it lives in the schema, the catalog, or the data dictionary — and the cost of that silence falls almost entirely on the teams downstream: analysts reverse-engineering column meanings from old Slack threads, ML engineers guessing at grain, executives squinting at dashboards quietly compromised by an undocumented default.
We're not alone in calling this out. Scroll through what the rest of the industry has been writing about it:
The schema serves more than just the app
The original purpose of an OLTP schema was modest: support fast, correct, concurrent transactions. Insert an order. Update a balance. Roll back if anything goes wrong. The relational model and normalization theory were designed for that workload, and forty years of production experience have refined the playbook to the point where most senior engineers can write a clean transactional schema in their sleep.
But OLTP schemas no longer serve only the application sitting on top of them. The same customers.email column now has to cooperate with:
- An ARR / revenue dashboard that joins customers to subscriptions to invoices, and needs to know which
emailfield —customers.email,subscriptions.contact_email, orinvoices.billing_email— is the source of truth when the three disagree. - A churn model in the data science team that wants the email domain, the signup vintage, and a stable definition of "active" that the product team keeps quietly changing.
- A growth team's cohort analysis that needs to know whether trial users, freemium users, and paid users all live in the same column or not.
- A sales ops view that wants to attribute revenue back to acquisition channel, source campaign, and account owner — none of which is in the OLTP schema by those names.
- A compliance pipeline that needs to know the field is PII so it can be redacted on request, encrypted at rest, and excluded from logs.
- An AI agent answering questions like "is this account a churn risk?" — using a column whose actual business meaning lives in a Slack thread from 2023.
Every one of those downstream consumers has to reverse-engineer the column's intent from its name. The schema gives them no help. The application code gives them outdated help. The wiki gives them stale help. The engineer who first added the column is at a different company.
The cost is not in the transaction. The cost is in everything downstream that has to guess what the transaction meant.
This is the gap modern OLTP design has to close, and it's why the textbook framing of schema design — normalize for integrity, index for performance — has stopped being enough on its own.
Schema work is no longer a one-time event
The old mental model is that schema design is something you do at the start of a system. You sit down, draw an ERD, hand it to the team, and then engineers write CRUD against it forever. Migrations are an unfortunate exception, not a discipline.
That model has been quietly broken for a while, and almost no tooling has caught up to it.
The reality of every production OLTP system we've seen:
- Schemas evolve weekly. A column gets added for a new feature. A table gets split because a domain matured. A constraint gets relaxed because a partner integration needed it.
- Most of those changes are made by engineers who weren't there when the original model was designed.
- Most of those changes are reviewed in PRs by people who don't know the historical context behind the affected tables.
- Most of those changes ship without anyone updating the documentation, the data dictionary, the catalog, or the downstream consumers.
In a fast-moving codebase, "we know what this column means" has a shelf life of months, not years. By the time you onboard your third backend engineer, half the schema is already running on tribal knowledge. The analytics team, the ML team, and the BI team pay interest on that debt every time they build on top of it.
OLTP schema design has quietly become a continuous practice — closer to how teams treat application code than how they treat infrastructure. And like application code, it needs the equivalent of code review, tests, linters, and a way for new contributors to understand the why behind what they're touching.
Where TalkingSchema starts
TalkingSchema is built around exactly this thesis: schema work as a continuous practice, with intent captured at design time and surfaced wherever it matters later — to the new engineer six months in, the analyst writing a cohort query, or the coding agent building features.
The most useful place to start that practice is the one bottleneck every schema change already passes through — the pull request.
The Git bot: making coding agents accountable to your schema
In 2026, most database changes don't originate in a modeling tool. They originate in a feature branch, written by an engineer working alongside a coding agent — Claude, Cursor, Codex, or whatever comes next. The engineer describes a feature, the agent generates the migration, the PR opens, the migration ships. The schema mutates. None of the feature conversation that produced the change makes it into the database, the catalog, or anywhere a future reader can find it.
Every PR is an intent-capture opportunity that almost every team is currently throwing away.
We're prototyping a Git bot that closes this loop.
When a PR touches anything schema-related, the bot blocks the merge with a required check and asks the coding agent to push the relevant context up to TalkingSchema first. The agent already has the feature conversation it had with the engineer — it just needs to surface it.
For anything the agent can't answer, it asks the engineer directly in the PR. If the engineer doesn't have the answer either, they can defer to a domain owner — and the question stays logged as a pending context request on TalkingSchema until someone closes it.
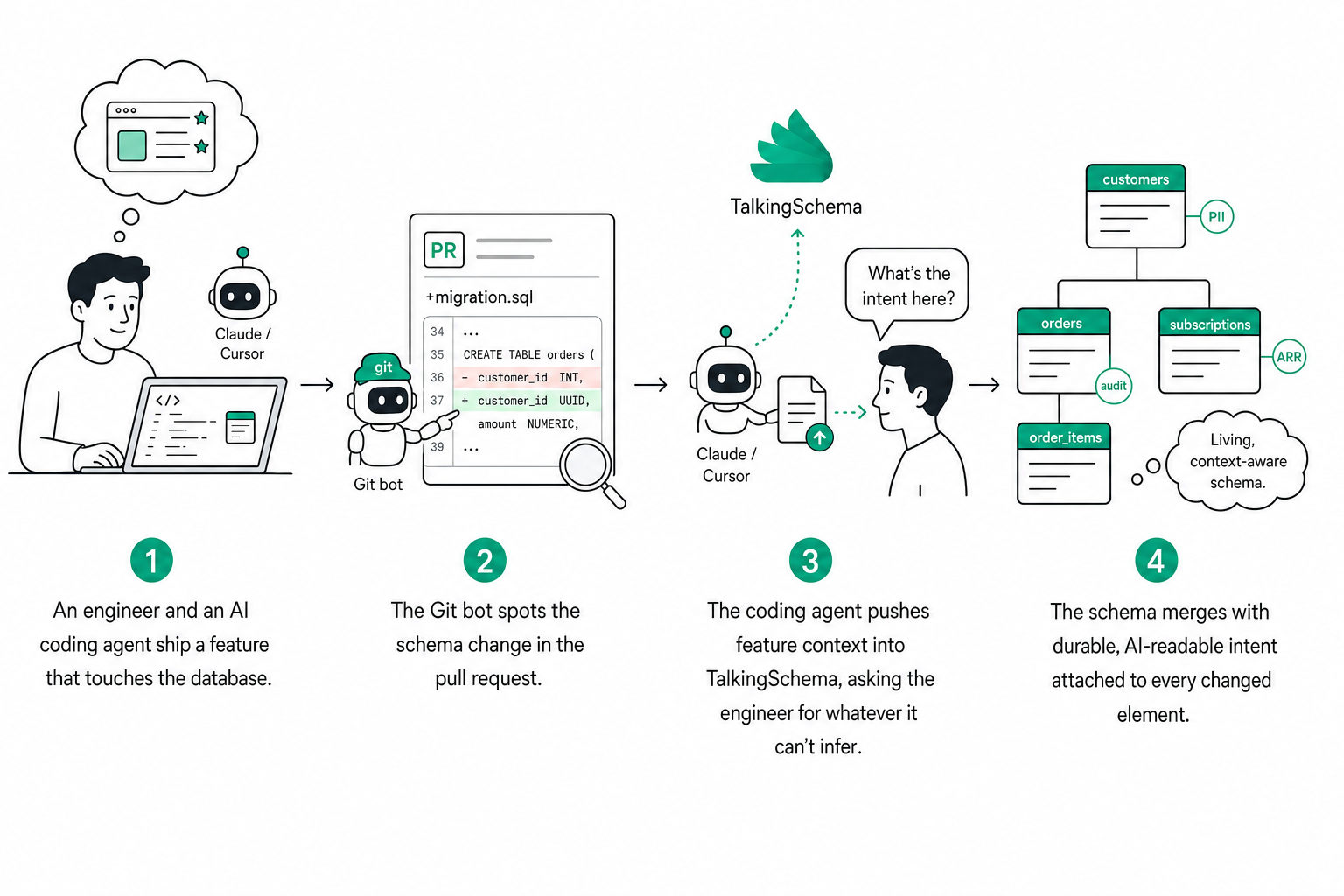
The point isn't to slow down database changes. It's to make sure every database change leaves the schema smarter than it found it.
Every PR is an intent-capture opportunity. The Git bot makes sure none of them are wasted.
See the difference: context-empty vs. context-rich
So what does a schema look like after six months of the Git bot running on every PR? Two structurally identical schemas — same tables, same columns, same indexes — make the difference visible.
Schema A — the typical OLTP database, no Git bot. Structurally correct. Normalized to 3NF. Hover over any element and you'll find brief technical descriptions: "Order status", "Product price in cents", "Seller tier." Enough to write a migration. Not enough to build a revenue model, a churn predictor, or a cohort analysis without going to hunt for more.
Schema B — the same database, six months in. Same shape. Every table note now tells you the grain, the owner, the downstream models that consume it, the KPIs it feeds, and the business rules that govern it. Hover over the elements and read through the notes.
The structural diff is zero. The semantic diff is everything a downstream team needs — and everything they're currently reverse-engineering from Slack threads and departed engineers.
Let's ask both schemas the very same question
The real test is what an agent does with the context. So take a question any marketplace exec would ask:
"Build me a model for GMV by buyer geography — total revenue per state, per month."
The agent's proposed model is baked into each canvas above as a table group called gmv_by_buyer_geography. Open both. The diff is one foreign key:
| Schema A (no context) | Schema B (with context) | |
|---|---|---|
| Fact table | gmv_by_state_month | gmv_by_state_month |
| Grain | (state, country, month) | (state, country, month) |
| How orders get geography | buyer_geo_dim — keyed by buyer_id (current address) | buyer_order_geo_snapshots — keyed by order_id (snapshot at checkout) |
That single column decides whether next year's regional revenue report tells the truth.
If you have worked in data warehousing, this is the slowly-changing-dimension problem in plain clothes. Buyer geography is not fixed forever; people move, edit addresses, delete addresses, and change defaults. A context-empty model treats geography like a current profile attribute. A context-rich model knows historical reporting needs the geography as it was when the order happened.
Schema A — the agent has to guess.
Nothing in the schema warns the agent that buyer geography changes over time. So the agent reaches for the easiest source available — the buyer's current shipping address:
Bug"We will derive buyer geography from the buyer's default shipping address — for most marketplaces, the default shipping address is the best simple proxy for 'where this buyer lives/operates.'"
As a result, buyer_geo_dim reflects whatever address each buyer has on file right now — not the address they had when each order was placed. So when a California buyer moves to New York in 2026 and updates their default address, every one of their historical 2024 California orders retroactively appears as a New York order.
The model compiles. The job runs. The dashboard looks exactly like the CFO asked for. A year of regional reporting silently rewrites itself, week by week, as buyers edit their profiles. There is no obvious error. No validation fires. Nobody catches it.
Schema B — the agent reads the note.
Run the same prompt against the context-rich schema. Before proposing a model, the agent flags a problem:
Correct"Given the current schema and the 'buyer geography is mutable' caveat, I'd model this as its own analytic group that uses snapshotted geography, not live addresses."
That "caveat" isn't something the agent guessed. It's a single CRITICAL: note on the buyer_addresses table — captured automatically by the Git bot the day an engineer added it — that warns anyone using the table for historical analysis to snapshot the address at order time instead.
That one note is the entire reason the agent reached for a snapshot table — an immutable point-in-time capture of geography at order time. buyer_order_geo_snapshots writes one row per order, captures the shipping state at the moment of checkout, and never updates it. The California buyer who moves to New York stays correctly attributed to California for every order they placed there.
Nothing in the columns, types, or foreign keys signals "this address is mutable in a way that breaks historical analysis." The shape of the data does not contain that fact. The captured intent does. The schema told the agent what the columns could not.
Same schema. Same buyer. Same orders. Two completely different models — one that will ship a corrupt geography chart to the board, and one that won't. The difference is whether the schema remembered to tell you.
The modeling inventory: from captured context to pre-built data models
Captured context compounds. A note written once silently shapes every model that touches the schema later — every cohort, every ML feature, every report, every coding agent that comes through.
But the compounding rarely happens. Most analytics teams are sitting on a deep backlog of models that this kind of context should be quietly powering — and every one of them still has to be designed from scratch.
The modeling inventory is that backlog, drafted in advance.
Once context about your transactional schema is reliable, TalkingSchema no longer has to wait for anyone to ask. It already understands the shape of the business: what tables exist, what each column means, where the grain lives, who owns each domain, and which KPIs matter. With that context, it can draft the downstream models a team is likely to need before they ask — as ready-to-review work.
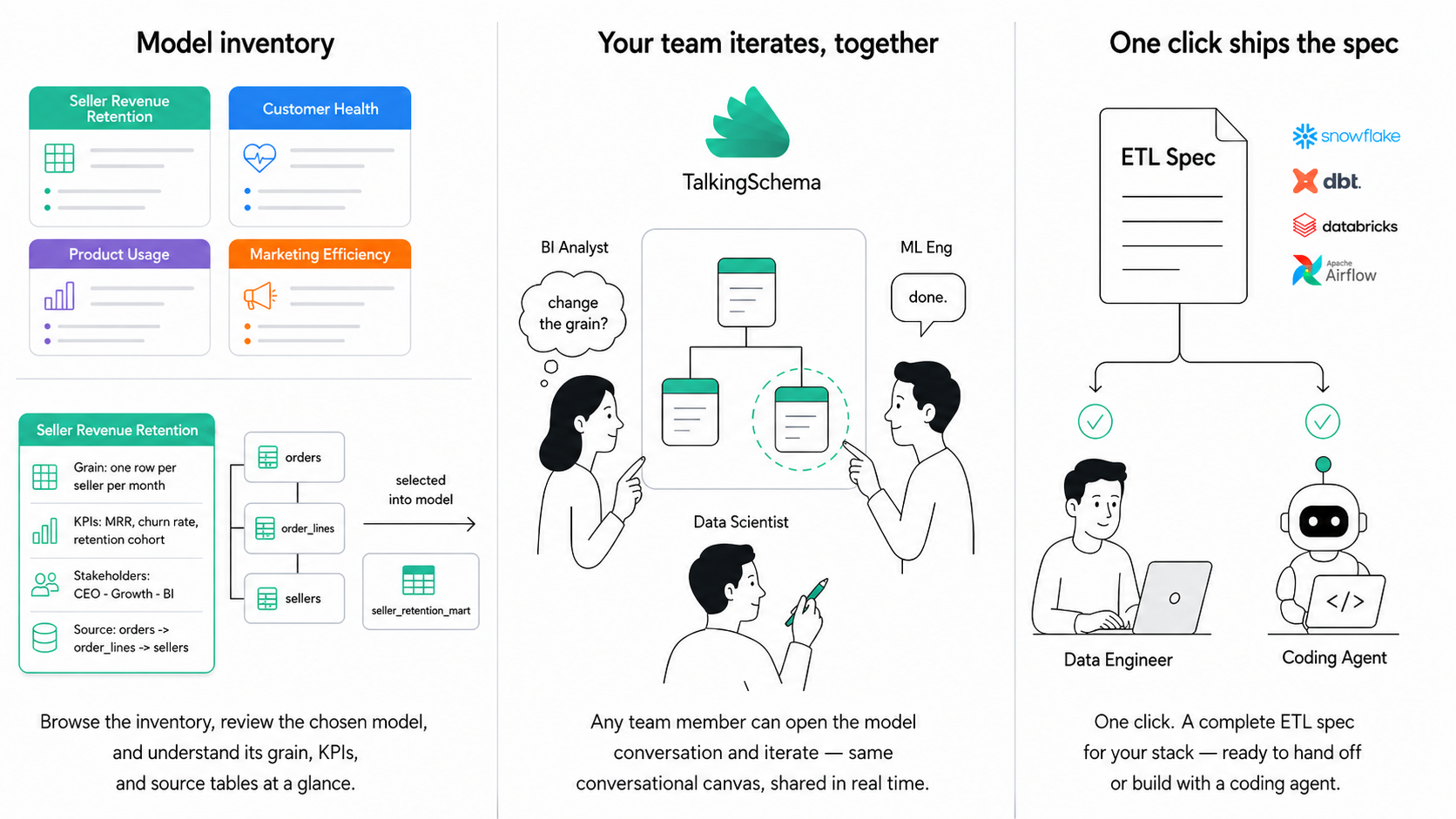
What gets pre-built. Each model lands as a data model file — an opinionated technical doc that explains the model in both business and technical terms (grain, primary keys, KPI definitions, compliance summary, lineage to OLTP source tables, sample queries, edge cases) and links directly into an ERD canvas where the model is already rendered. Not a wireframe. Not a placeholder. An actual proposed model that the team can read end-to-end on day one.
How models are organized. Pre-built models are grouped along two axes data teams already think in:
- By business domain — Revenue, Customer, Product, Marketing, Operations, Finance. Each domain surfaces every model that touches that subject area. Opening Revenue shows you cohort tables, subscription facts, and payout marts.
- By model type — Marts (aggregated, BI-ready rollups for dashboards), Feature stores (entity-grain, point-in-time-correct for ML training and inference), and Dimensional models (star/snowflake schemas for ad-hoc analytical querying). Every analytics engineer and data scientist immediately knows which shelf to reach for.
Iterating on a proposed model. No pre-built model ships perfect.
Say the ML team opens the Customer Churn Feature Set and realizes it's missing a feature: days since last login, in both a 7-day and 30-day rolling version. They don't file a ticket. They open the model in TalkingSchema's ERD canvas, describe the change, and it's done. The model updates, lineage stays intact, and everyone using it sees the revision immediately.
Shipping the model. Once the team is satisfied, one click turns the model into a pipeline spec for their stack — Snowflake, Databricks, or BigQuery with dbt or Airflow on top — covering source tables, transformations, grain, tests, and SLAs.
From there, refine it further with TalkingSchema, or hand it off to an engineer or coding agent to build.
A downstream model stops being a six-week project that starts with a Slack ping. It becomes a piece of work that's already 80% drafted by the time the team opens TalkingSchema, and gets shipped through the same conversation that refined it.
That's the bet. The modeling inventory is a shelf of ready-to-ship downstream models, grouped for the people who actually need them, and one click away from a pipeline spec their stack can build.
Advanced Modeling: every possibility, not just the obvious ones
The real promise of Advanced Modeling is that it expands what your business can think to ask — beyond what your team already knows it needs.
Today, someone — usually a senior analytics engineer or data lead — drives the modeling agenda. They build the models they can think of. The ones they can't think of never exist. This isn't a failure of talent. It's a failure of surface area: no single person can enumerate every analytically meaningful slice of a complex transactional schema. Not the senior engineer. Not the data lead. Not a team of four.
There's a clean way to state the asymmetry:
|Mpossible| ≫ |Mbuilt|
The set of analytical models a schema could power grows combinatorially with tables, grains, KPIs, and segmentations. The set a team has actually built grows linearly with headcount and the quarters available. The gap widens every time the schema does.
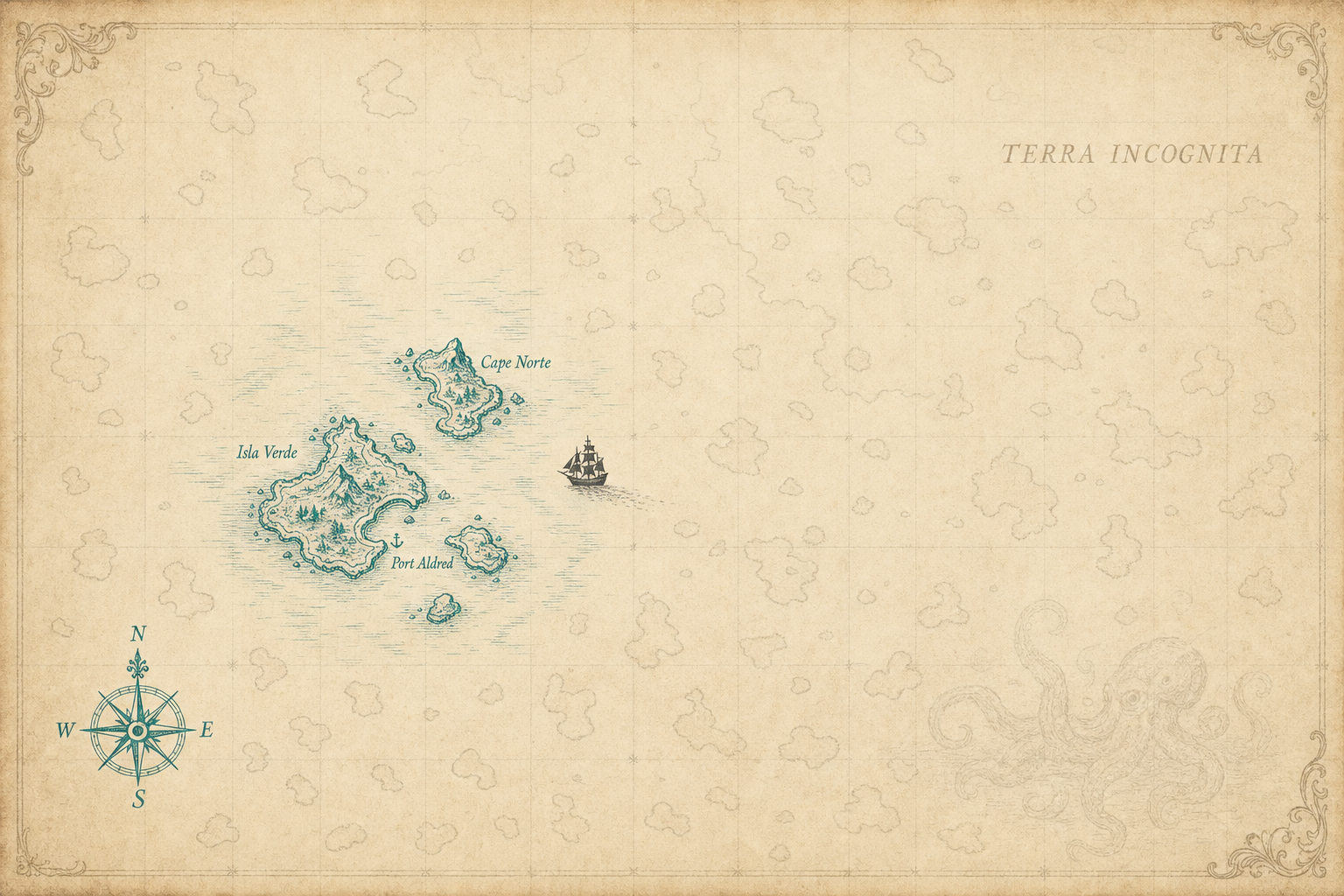
A few islands carefully explored. The rest of the archipelago is already there — just waiting to be discovered.
Advanced Modeling changes the calculus.
When TalkingSchema has full context on your OLTP schema, it can enumerate the models itself. Every analytically coherent grain. Every fact-to-dimension relationship. Every KPI that can be derived from the data that already exists. The modeling inventory becomes the complete set of business questions your current data can answer.
For most organizations, that inventory is startlingly large. And startlingly underexploited.
The most consequential reader of it is the executive — because every executive operates from a mental model of the business that was assembled, often years ago, by whichever team lead had two weeks and a vague brief. The quality of every strategic decision they make is bounded by the quality of that assembled model. What they rarely have is a complete picture of what their data can tell them.
TalkingSchema gives leaders a common analytical surface across the business — Revenue, Customer, Product, Marketing, Operations, Finance. The executive stops being dependent on whichever subject matter expert happened to propose the questions worth asking.
The shape of the problem is familiar to anyone who's looked at a power law:
Attention spent on analytical models follows a long-tail distribution. A handful of obvious dashboards — revenue, churn, retention — absorb almost all the attention. The long tail of strategy-changing models almost never gets touched, even though that's where the leverage usually lives.
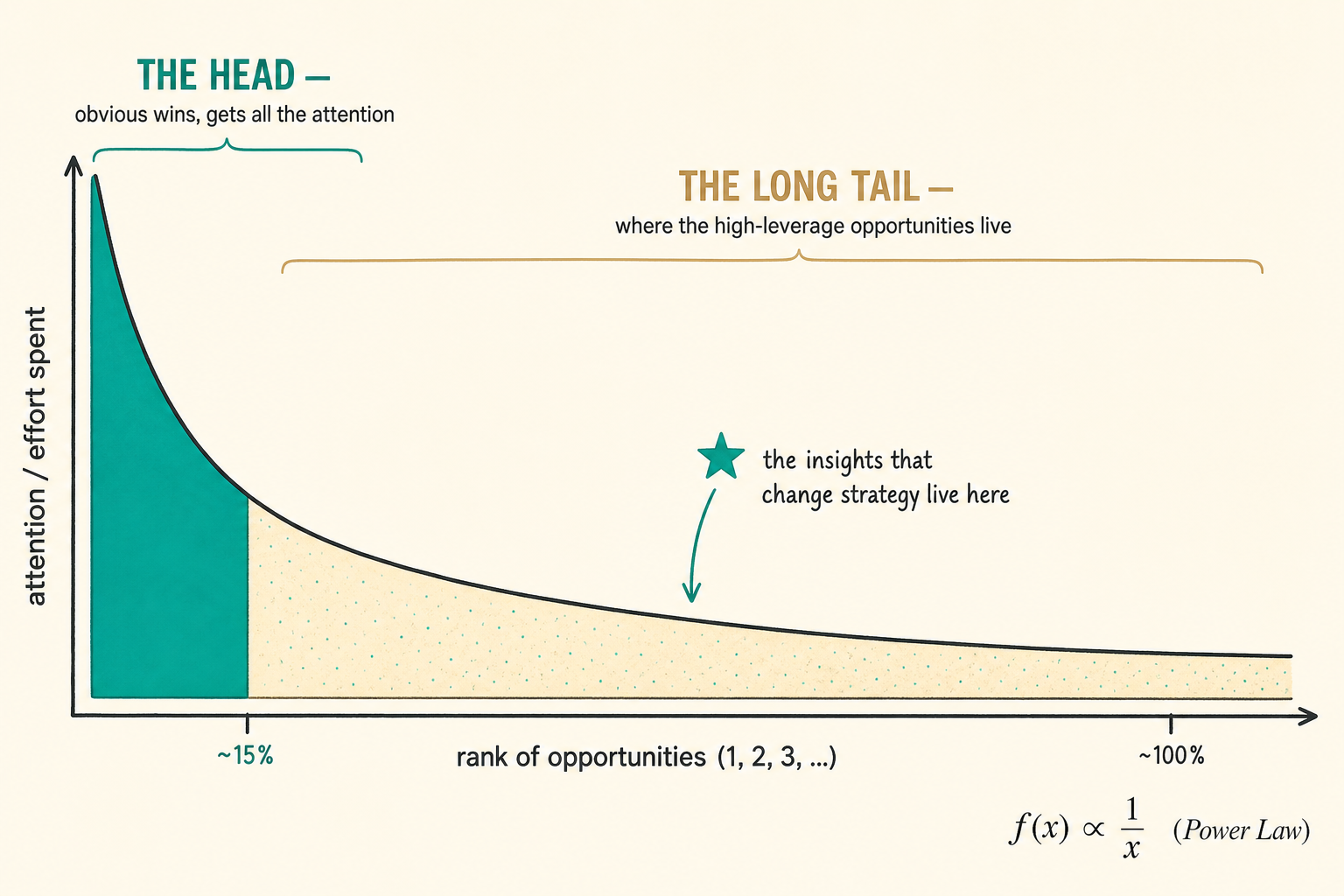
That is not a small thing. The models that never get built are the ones that contain the insights that change strategy — and they don't get built not because they're hard, but because no one had the context to know they were possible.
The inventory makes them visible. The questions nobody knew to ask, whose answers were already sitting in your database, finally get asked.
Start with your existing schema. Import it, bring in the context you already have, and see the modeling inventory it generates. The questions your data can answer have always been there. Now there's a way to see all of them at once.